Op deze pagina wordt de beschrijving gegeven voor het maken van de structuur van een export uit een DMS (Document Management System) voor de overbrenging van de content (in DMS-termen: archief, rubrieken, series, dossiers, subdossiers, documenten en versies van documenten/records) en de metadata van het DMS naar het E-depot. De beschrijving richt zich eerst op een initiële export uit het DMS, dus ten behoeve van een nieuw archief in het E-depot. In de laatste paragraaf wordt beschreven hoe vervolgexporten voor toevoegingen aan een bestaand archief in het e-Depot, zogenoemde supplementen, eruit moeten zien. Om bij de initiële export goed voorbereid te zijn op supplementen komen in paragraaf 7 supplementen ook al kort aan bod.
De export moet een zogenoemde sidecar-structuur hebben. In deze structuur zit de content in een directory-structuur: elk dossier, subdossier en archiefstuk is een map, elke versie van een document is een bestand. Elke map (dossier, subdossier, archiefstuk) en elk bestand (versie van een document) heeft zijn eigen metadatabestand, een zogenoemde sidecar. De naam van een metadatabestand is identiek aan die van de map of bestand waar het bij hoort, aangevuld met de extensie ‘.opex’. De plaats van een metadatabestand dat bij een map hoort, is in deze map. De plaats van een metadatabestand dat bij een bestand hoort, is naast dit bestand.
In de Nederlandse archiefwereld kent men vijf types aggregatieniveau. Het hoogste aggregatieniveau is van het type archief. Daarna volgen er meestal één of meerdere aggregatieniveaus van het type serie. Dit type aggregatieniveau is niet verplicht. Dan volgt er ten minste één aggregatieniveau van het type dossier. Let wel: in de archiefwereld is een dossier niet per se hetzelfde als in de DMS-wereld. Dan volgen er in de regel één of meerdere aggregatieniveaus van het type archiefstuk, hoewel dit aggregatieniveau niet in alle gevallen verplicht is. De vier tot nu toe genoemde types aggregatieniveau komen overeen met de DMS mappen (dossiers, subdossiers en archiefstukken) in de export, waarbij rubriek en serie als
metagegevens in de metadata van het dossier behoren te worden opgenomen. Hieronder een voorbeeld:
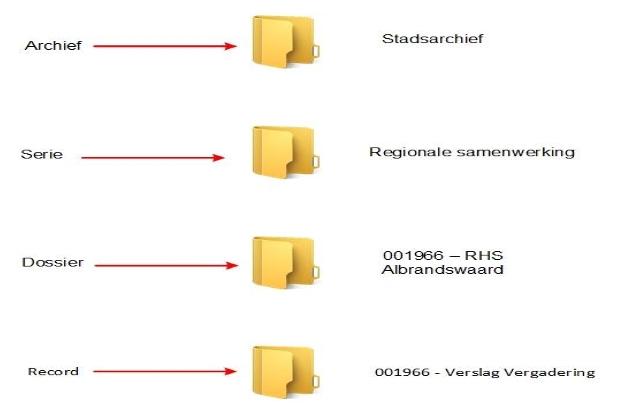
De serie wordt toegevoegd aan de mapping structuur van het dossier.
Het laagste aggregatieniveau is van het type bestand. Wat in de archiefwereld een bestand heet, is feitelijk niets anders dan wat in de DMS-wereld een versie van een document is.
Hieronder als voorbeeld de inhoud van archiefstuk ofwel map 001966 – Verslag Vergadering in het vorige plaatje.
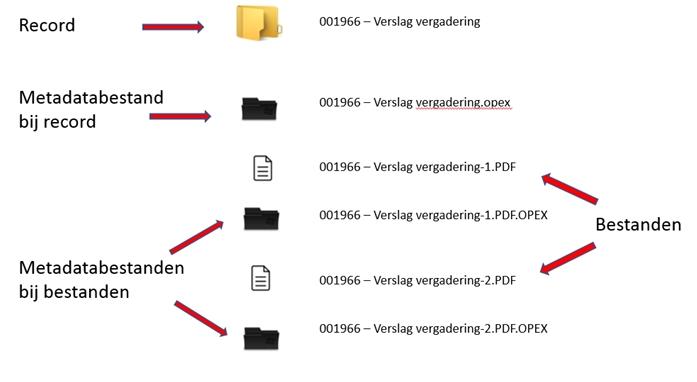
Het archiefstuk bevat dus:
- het metadatabestand bij het archiefstuk ‘001966 – Verslag Vergadering ’
- de bestanden ‘001966-001966 – Verslag Vergadering -1.PDF’ en ‘001966 – Verslag Vergadering -2.PDF’
- de metadatabestanden bij deze twee bestanden, te weten ‘001966-001966 – Verslag Vergadering -1.PDF.opex respectievelijk ‘001966-001966 – Verslag Vergadering 2.PDF.opex
Hieronder de vier types aggregatieniveaus in een tabel:
| Type | Niveau | Aantal aggregatieniveaus |
| Archief | Hoogste niveau | 1 aggregatieniveau |
| Serie | Tweede tot en met N-de | 1... N |
| Dossier | Tweede tot en met N-de niveau | 1... N |
| Archiefstuk | (N+1) de tot en met één na laagste niveau |
|
| Bestand | Laagste niveau | 0 of 1 aggregatieniveau |
Een bestand hangt in de regel niet rechtstreeks onder een dossier. Er zit gewoonlijk ten minste één archiefstuk-niveau tussen een dossier en een bestand om verschillende versies van en/of bijlagen bij een document te kunnen aggregeren. In de volgende paragraaf volgt hierover een uitgebreidere beschrijving. Alleen in het geval dat een document maar één versie kent en geen bijlagen heeft, is het bestand feitelijk ook het document en mag het dus rechtstreeks onder het dossier hangen.
Spil in de bepaling van de types van de aggregatieniveaus in de export is de bepaling van het hoogste aggregatieniveau van type dossier. Op dit niveau worden alle documenten met betrekking tot één zaak geaggregeerd. In DMS-termen zitten we dan vaak op het niveau van de dossiers, maar soms ook op het/een niveau van de subdossiers.
Zodra duidelijk is welk niveau in het DMS overeenkomt met het hoogste aggregatieniveau van het type dossier, kunnen de types van de andere aggregatieniveaus eenvoudig worden afgeleid. Alle mappen boven het hoogste aggregatieniveau van type dossier zijn van het type serie, behoudens de hoogste, die van het type archief is. De mappen onder het hoogste aggregatieniveau van type dossier mogen allen van het type archiefstuk zijn, maar ook eerst nog van het type dossier zolang er geen sprake is van de aggregatie van versies van en/of bijlagen bij een document, want vanaf daar dient het type archiefstuk gebruikt te worden. Wat nu nog resteert, zijn de bestanden, die uiteraard van het laagste aggregatieniveau van type bestand zijn.
Aggregatieniveaus van het type archiefstuk kunnen dienen voor het aanbrengen van een ordening in subdossiers binnen een dossier (of binnen een hoger subdossier), maar moeten in elk geval gebruikt worden voor het bijeenhouden van verschillende versies van en/of bijlagen bij een document. Zijn er verschillende versies van een document of zijn er bijlagen, dan zijn deze alle terug te vinden in één archiefstuk. Zo bevat het archiefstuk ‘001966-Verslag Vergadering’ in het eerder gebruikte voorbeeld twee versies van het document ‘001966-Verslag Vergadering’, te weten ‘001966-Verslag Vergadering-1.PDF’ en ‘001966-Verslag-2.PDF’. Van bijlagen is in het voorbeeld geen sprake, maar bij het opslaan van e-mails kan er wel sprake zijn van bijlagen.
In sommige DMS-en zit(ten) verschillende versies van een/de bijlage(n) bij een document in een map naast de versies van dit document. Dan is het toegestaan om in de export die map als record op te nemen. Zo ontstaat er een onderliggend aggregatieniveau van het type archiefstuk. Omdat bijlagen ook bijlagen kunnen hebben, kunnen daaronder ook weer aggregatieniveaus van het type archiefstuk ontstaan.
De export mag alleen afgesloten dossiers bevatten. Dossier wordt hier bedoeld als type aggregatieniveau in de Nederlandse archiefwereld. Nog lopende dossiers in het DMS worden dus niet meegenomen in de export.
De metadatabestanden worden gevuld met MDTO 1.0.1-metadata conform de mapping die tevoren in een excel bestand is gemaakt en waarin de vertaalslag van de metadata-elementen in het DMS naar de MDTO 1.0.1-metadata-elementen is vastgelegd. Deze mapping is in samenwerking tussen de overdragende organisatie en het Stadsarchief tot stand gekomen. Daarbij komt dat in het eindelijke metadatabestand een header en een footer met zogenoemde OPEX-informatie in XML-formaat moet worden toegevoegd om de opname in de e-depot software mogelijk te maken. Aanleveringen met metadata in ToPX 2.3.2 worden ook geaccepteerd door het Stadsarchief Rotterdam, maar MDTO 1.0.1 heeft de voorkeur.
Voor het vullen kan gebruik worden gemaakt van onderstaand vijftal viertal sjablonen (voor het aggregatieniveau Archief kan het sjabloon voor Serie worden gebruikt):
- Voor metadatabestanden bij de series: MDTO-XML 1.0.1 Voorbeeld Serie Informatieobject
- Voor metadatabestanden bij de dossiers: MDTO-XML 1.0.1 Voorbeeld Dossier Informatieobject
- Voor metadatabestanden bij de archiefstukken: MDTO-XML 1.0.1 Voorbeeld Archiefstuk Informatieobject
- Voor metadatabestanden bij de bestanden: MDTO-XML 1.0.1 Voorbeeld Bestand_max.xml
In deze sjablonen moeten alle MDTO 1.0.1-metadata-elementen verwijderd worden, waarvoor in afstemming met de organisatie is overeengekomen dat deze niet gevuld zullen worden, of deze MDTO 1.0.1-metadata-elementen kunnen tussen commentaar-tags gezet worden. Deze actie is nodig om te voorkomen dat bij controle met behulp van de xsd, waarin de voorwaarden staan waaraan de MDTO 1.0.1-metadata-elementen in de metadatabestanden moeten voldoen, fouten worden geconstateerd met betrekking tot MDTO 1.0.1-metadata-elementen die niet leeg mogen zijn indien aanwezig.
De controle met behulp van de xsd is één van de controles die het e-Depot doet om te bepalen of de export in het e-Depot mag worden ingelezen. Hieronder is een link naar deze xsd, zodat de archiefvormer zelf kan controleren of de export voldoet aan de MDTO 1.0.1-eisen alvorens deze naar het e-Depot te versturen: MDTO-xsd
In de metadatabestanden moeten ook de OPEX-header en -footer worden toegevoegd zoals in de metadatabestanden in het ‘Voorbeeld van een SIP structuur’ kan worden gezien. De metadatabestanden dienen te worden opgeslagen met karaktercodering UTF-8 (8-bit Unicode Transformation Format) zonder BOM (Byte Order Mark).
Hoewel de vulling van de MDTO 1.0.1-metadata-elementen wordt afgestemd in de mapping die tevoren in een excel bestand is gemaakt, moet in dit document toch worden ingaan op MDTO 1.0.1-metadata-element 2: identificatiekenmerk. Dit element moet namelijk aan een aantal technische eisen voldoen die essentieel zijn om toevoegingen aan bestaand archief (supplementen) mogelijk te maken.
De technische eisen met betrekking tot MDTO 1.0.1-metadata-element 2: identificatiekenmerk, in een export zijn:
- Het identificatiekenmerk van het archief is het beheernummer dat door het Stadsarchief is verstrekt
- Het archief en elke serie binnen het archief heeft een identificatiekenmerk dat uniek is binnen deze groep.
- Elk dossier en elk archiefstuk binnen het archief hebben een identificatiekenmerk dat uniek is binnen deze groep.
- Het identificatiekenmerk van een serie of een dossier moet uniek afleidbaar zijn (of in geval de serie of het dossier wegens vernietiging niet meer bestaat in het DMS: zijn geweest) uit de gegevens in het DMS.
- Elk dossier en alles wat eronder zit mag maar één keer worden aangeleverd.
- Een identificatiekenmerk mag uit niet meer dan 255 karakters bestaan.
Voor het creëren van de sidecar-structuur kunnen de mappen-en-bestanden-structuur van het
besturingssysteem gebruikt worden. Hierbij gelden de volgende technische beperkingen:
- Map- en bestandsnamen mogen niet de volgende karakters bevatten: < > : “ / \ | ? * en #
De map- en bestandsnamen moeten geschoond worden van deze karakters. - Map- en bestandsnamen mogen niet identiek zijn aan: CON, PRN, AUX, NUL, COM1, COM2, COM3, COM4, COM5, COM6, COM7, COM8, COM9, LPT1, LPT2, LPT3, LPT4, LPT5, LPT6, LPT7, LPT8 of LPT9. Uiteraard mag een map- of bestandsnaam deze strings wel bevatten. Map- en bestandsnamen die identiek zijn aan één van de genoemde strings, moeten veranderd worden.
Het is aan te raden om bij een heel groot archief de SIP in verschillende deelbatches over te brengen. We gaan uit van een maximum van ongeveer 500 GB. Dit heeft niet alleen te maken met de grootte van de batch, maar ook van het aantal documenten. De splitsing van een batch wordt idealiter gemaakt op het aggregatieniveau serie, die zich direct onder het archief bevinden. Voor de daadwerkelijke overdracht worden hierover concrete afspraken gemaakt.